Pengertian
Pada
artikel kali ini kita akan mengenal tentang ‘Bioinformatika’. Apa sih
itu bioinformatika? Memang sudah begitu banyak artikel yang membahas
tentang istilah ini, akan tetapi tidak ada salahnya kalau saya mencoba
mengulas kembali dari sisi yang sedikit berbeda. Istilah ini berasal
dari bahasa Inggris yaitu bioinformatics, yang artinya ilmu yang
mempelajari tentang penerapan teknik komputasional untuk mengelola dan
menganalisis informasi biologis (kalau kata wikipedia ^^). Akan tetapi
kalau saya boleh sederhanakan menggunakan kata-kata sendiri,
bioinformatika adalah segala bentuk penggunaan komputer dalam menangani
masalah-masalah biologi. Dalam prakteknya, definisi yang digunakan oleh
kebanyakan orang adalah satu sinonim dari komputasi biologi molekul
(penggunaan komputer dalam menandai karakterisasi dari komponen-komponen
molekul dari makhluk hidup). Sedangkan menurut Fredj Tekaia dari
Institut Pasteur [TEKAIA 2004], Bioinformatika (Klasik) adalah “metode
matematika, statistik dan komputasi yang bertujuan untuk menyelesaikan
masalah-masalah biologi dengan menggunakan sekuen DNA dan asam amino dan
informasi-informasi yang terkait dengannya”.
Jadi,
Bioinformatika ini merupakan ilmu terapan yang lahir dari perkembangan
teknologi informasi dibidang molekular. Pembahasan dibidang
bioinformatika ini tidak terlepas dari perkembangan biologi molekular
modern, salah satunya peningkatan pemahaman manusia dalam bidang genomic
yang terdapat dalam molekul DNA.
Kemampuan untuk memahami dan memanipulasi kode genetik DNA ini sangat
didukung oleh teknologi informasi melalui perkembangan hardware dan
soffware. Baik pihak pabrikan sofware dan harware maupun pihak ketiga
dalam produksi perangkat lunak. Salah satu contohnya dapat dilihat pada
upaya Celera Genomics, perusahaan bioteknologi Amerika Serikat yang
melakukan pembacaan sekuen genom manusia yang secara maksimal
memanfaatkan teknologi informasi sehingga bisa melakukan pekerjaannya
dalam waktu yang singkat (hanya beberapa tahun).
Sejarah
Istilah ''bioinformatics'' mulai dikemukakan pada pertengahan era [[1980-an]] untuk mengacu pada penerapan [[komputer]] dalam biologi. Namun demikian, penerapan bidang-bidang dalam bioinformatika (seperti pembuatan basis data dan pengembangan [[algoritma]] untuk analisis [[sekuens biologis]]) sudah dilakukan sejak tahun [[1960-an]].
Kemajuan teknik [[biologi molekular]] dalam mengungkap sekuens biologis dari protein (sejak awal [[1950-an]]) dan [[asam nukleat]] (sejak 1960-an) mengawali perkembangan basis data dan teknik analisis sekuens biologis. Basis data sekuens protein mulai dikembangkan pada tahun 1960-an di [[Amerika Serikat]], sementara basis data sekuens DNA dikembangkan pada akhir 1970-an di Amerika Serikat dan [[Jerman]] (pada ''European Molecular Biology Laboratory'', Laboratorium Biologi Molekular [[Eropa]]). Penemuan teknik [[sekuensing]] DNA yang lebih cepat pada pertengahan 1970-an menjadi landasan terjadinya ledakan jumlah sekuens DNA yang berhasil diungkapkan pada 1980-an dan [[1990-an]], menjadi salah satu pembuka jalan bagi proyek-proyek pengungkapan [[genom]], meningkatkan kebutuhan akan pengelolaan dan analisis sekuens, dan pada akhirnya menyebabkan lahirnya bioinformatika.
Perkembangan [[Internet]] juga mendukung berkembangnya bioinformatika. Basis data bioinformatika yang terhubung melalui Internet memudahkan ilmuwan mengumpulkan hasil sekuensing ke dalam basis data tersebut maupun memperoleh sekuens biologis sebagai bahan analisis. Selain itu, penyebaran [[program]]-program aplikasi bioinformatika melalui Internet memudahkan ilmuwan mengakses program-program tersebut dan kemudian memudahkan pengembangannya.
Kemajuan teknik [[biologi molekular]] dalam mengungkap sekuens biologis dari protein (sejak awal [[1950-an]]) dan [[asam nukleat]] (sejak 1960-an) mengawali perkembangan basis data dan teknik analisis sekuens biologis. Basis data sekuens protein mulai dikembangkan pada tahun 1960-an di [[Amerika Serikat]], sementara basis data sekuens DNA dikembangkan pada akhir 1970-an di Amerika Serikat dan [[Jerman]] (pada ''European Molecular Biology Laboratory'', Laboratorium Biologi Molekular [[Eropa]]). Penemuan teknik [[sekuensing]] DNA yang lebih cepat pada pertengahan 1970-an menjadi landasan terjadinya ledakan jumlah sekuens DNA yang berhasil diungkapkan pada 1980-an dan [[1990-an]], menjadi salah satu pembuka jalan bagi proyek-proyek pengungkapan [[genom]], meningkatkan kebutuhan akan pengelolaan dan analisis sekuens, dan pada akhirnya menyebabkan lahirnya bioinformatika.
Perkembangan [[Internet]] juga mendukung berkembangnya bioinformatika. Basis data bioinformatika yang terhubung melalui Internet memudahkan ilmuwan mengumpulkan hasil sekuensing ke dalam basis data tersebut maupun memperoleh sekuens biologis sebagai bahan analisis. Selain itu, penyebaran [[program]]-program aplikasi bioinformatika melalui Internet memudahkan ilmuwan mengakses program-program tersebut dan kemudian memudahkan pengembangannya.
Penerapan
Prediksi Struktur Protein
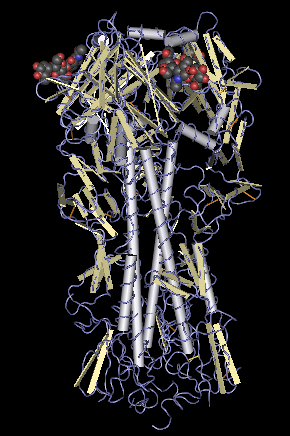
Secara kimia/fisika, bentuk struktur protein diungkap dengan kristalografi sinar-X ataupun spektroskopi NMR, namun kedua metode tersebut sangat memakan waktu dan relatif mahal. Sementara itu, metode sekuensing protein relatif lebih mudah mengungkapkan sekuens asam amino protein. Prediksi struktur protein berusaha meramalkan struktur tiga dimensi protein berdasarkan sekuens asam aminonya (dengan kata lain, meramalkan struktur tersier dan struktur sekunder berdasarkan struktur primer protein). Secara umum, metode prediksi struktur protein yang ada saat ini dapat dikategorikan ke dalam dua kelompok, yaitu metode pemodelan protein komparatif dan metode pemodelan de novo.
Pemodelan protein komparatif (comparative protein modelling) meramalkan struktur suatu protein berdasarkan struktur protein lain yang sudah diketahui. Salah satu penerapan metode ini adalah pemodelan homologi (homology modelling), yaitu prediksi struktur tersier protein berdasarkan kesamaan struktur primer protein. Pemodelan homologi didasarkan pada teori bahwa dua protein yang homolog memiliki struktur yang sangat mirip satu sama lain. Pada metode ini, struktur suatu protein (disebut protein target) ditentukan berdasarkan struktur protein lain (protein templat) yang sudah diketahui dan memiliki kemiripan sekuens dengan protein target tersebut. Selain itu, penerapan lain pemodelan komparatif adalah protein threading yang didasarkan pada kemiripan struktur tanpa kemiripan sekuens primer. Latar belakang protein threading adalah bahwa struktur protein lebih dikonservasi daripada sekuens protein selama evolusi; daerah-daerah yang penting bagi fungsi protein dipertahankan strukturnya. Pada pendekatan ini, struktur yang paling kompatibel untuk suatu sekuens asam amino dipilih dari semua jenis struktur tiga dimensi protein yang ada. Metode-metode yang tergolong dalam protein threading berusaha menentukan tingkat kompatibilitas tersebut.
Dalam pendekatan de novo atau ab initio, struktur protein ditentukan dari sekuens primernya tanpa membandingkan dengan struktur protein lain. Terdapat banyak kemungkinan dalam pendekatan ini, misalnya dengan menirukan proses pelipatan (folding) protein dari sekuens primernya menjadi struktur tersiernya (misalnya dengan simulasi dinamika molekular), atau dengan optimisasi global fungsi energi protein. Prosedur-prosedur ini cenderung membutuhkan proses komputasi yang intens, sehingga saat ini hanya digunakan dalam menentukan struktur protein-protein kecil. Beberapa usaha telah dilakukan untuk mengatasi kekurangan sumber daya komputasi tersebut, misalnya dengan superkomputer (misalnya superkomputer Blue Gene [1] dari IBM) atau komputasi terdistribusi (distributed computing, misalnya proyek Folding@home) maupun komputasi grid.
SUMBER :
http://id.wikipedia.org/wiki/Bioinformatika
http://ianspace.wordpress.com/2011/05/01/bioinformatika/
Komentar:
Dari artikel diatas saya dapat menyimpulkan bahwa bioinformatika sangatlah memiliki peran yang mendasar di berbagai bidang khususnya bidang kesehatan, dimana pada artikel ini bioinformatika mampu memprediksi struktur protein yang ada didalam tubuh seseorang, sehingga memudahkan paru pelaku kesehatan dalam melakukan pekerjaannya.
Rudy Afriadi
51409091
4IA07
1 komentar:
Dari artikel diatas saya dapat menyimpulkan bahwa bioinformatika sangatlah memiliki peran yang mendasar di berbagai bidang khususnya bidang kesehatan, dimana pada artikel ini bioinformatika mampu memprediksi struktur protein yang ada didalam tubuh seseorang, sehingga memudahkan paru pelaku kesehatan dalam melakukan pekerjaannya.
Posting Komentar